


What is Lead Time for Changes?
Lead Time for Changes is a DORA metric which measures the time taken to go from code committed to code successfully running in production.
Lead Time for Changes, also called Change Lead Time or LTFC, is defined in Accelerate: The Science of Lean Software and DevOps (which popularized the DORA metrics) as ‘the time taken to go from code committed to code successfully running in production.' It's similar to the Code Cycle Time metric, and is a core DevOps metric.
Code Cycle Time is a broader metric in that it provides insight into the different stages that a pull request goes through and the time to deploy. These stages are defined as:
Time to Review: from open to the first comment or review
Time to Approve: from the previous stage to approved
Time to Merge (Commit)/Close: from the previous stage to merge/close
Time to Deploy: from the previous stage to deployed to production
LTFC however, only focuses on the final two stages listed above.
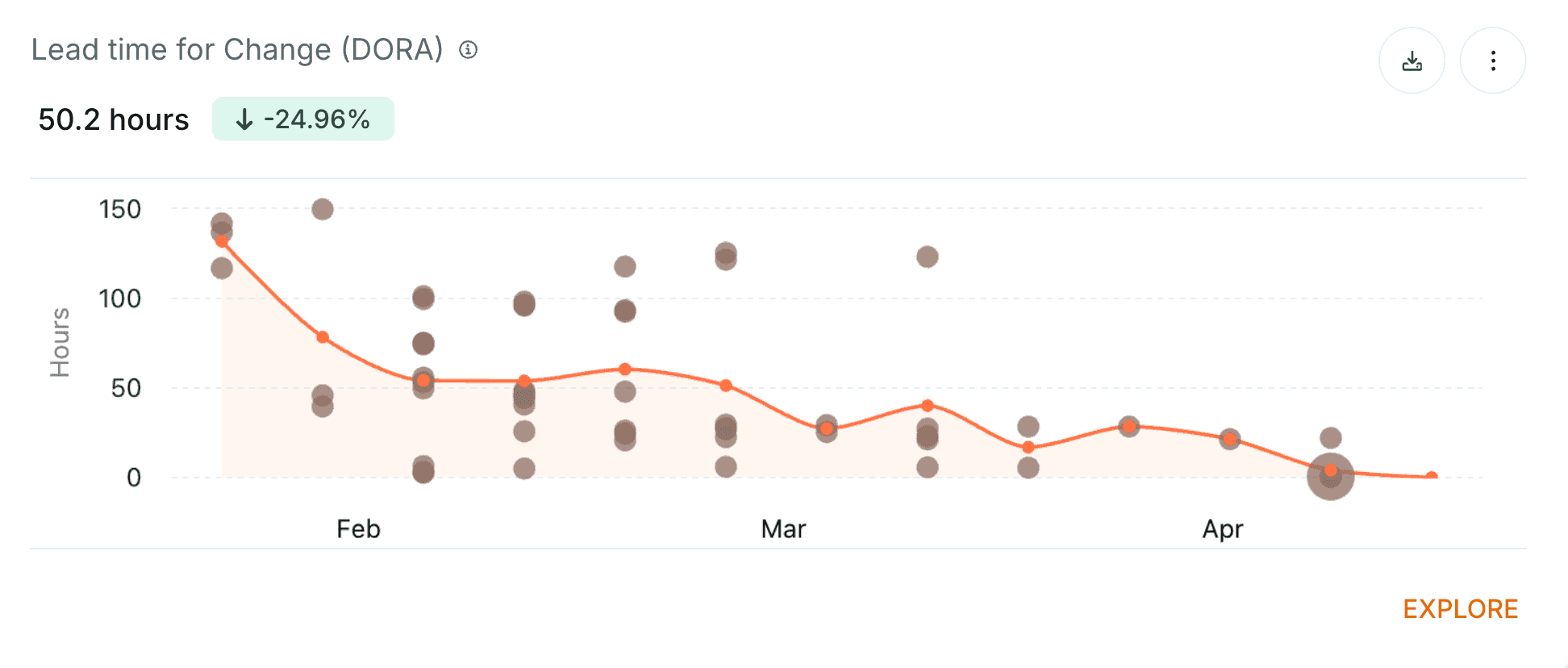
What causes long Lead Time for Changes?
Long Lead Time for Changes is usually caused by bottlenecks in the delivery system.
LTFC typically accounts for around 30% of Cycle Time.
The pull request process is one of the most common blockers, often because teams rely on a few key engineers to action the majority of PRs. As PRs cluster around those individuals, bottlenecks develop rapidly.
Common causes include:
PRs waiting for review
unclear ownership or approval paths
inconsistent review standards
merge conflicts or dependency coordination
batching changes for release
manual deployment gates or fixed release windows
This is why LTFC is best understood as a flow metric, not just a speed metric. It shows how efficiently committed code moves through the system, and where it starts to queue.
If we want to improve LTFC, we should usually start by finding where committed code is waiting, who it is waiting on, and which bottleneck is limiting flow.
Critically, classic queueing delays are largely invisible. They don’t show up as “slow engineering”, but rather as time passing in bottlenecks.
Learn more about how to identify and fix software engineering bottlenecks here.
Benchmarks for Lead Time for Changes
Our benchmarks are taken from the Accelerate State of DevOps
Elite team: LTFC less than 1 hour;
High-performing teams: LTFC between 1 hour and 1 week;
Medium-performing teams: LTFC between 1 week and 6 months;
Low-performing teams: LTFC more than 6 months.
Why Lead Time for Changes matters
It’s easy to treat Lead Time for Changes as a speed metric. That’s too narrow. In practice, it’s a systems signal: it tells us how well committed code flows through review, merge and deployment into production.
Delivery predictability
Stable, low lead times make planning more reliable. Releases are easier to forecast, stakeholders have more confidence in timelines, and roadmap commitments become less fragile. Unstable LTFC usually points to hidden variability: queues, handoffs, unclear ownership or inconsistent processes across teams.
Feedback loops
Shorter lead times mean faster feedback. Code reaches users sooner, teams learn faster, and product decisions improve because they are based on real usage rather than assumptions.
Risk reduction
Reducing LTFC can also reduce delivery risk. Smaller changes are easier to review, test, deploy and roll back. Long lead times often create larger, more complex releases, and that’s where failures hide.
Developer experience
Long lead times create frustration. Engineers wait for PR reviews, chase approvals, lose context and carry unnecessary cognitive load.
When flow improves, teams spend less time waiting and more time delivering value. That improves productivity, but it also improves morale.
How to measure Lead Time for Changes
Measuring Lead Time for Changes properly starts with one basic discipline: be clear about where the clock starts and stops.
For DORA, LTFC measures the time from code committed to code successfully running in production. The cleanest definition is:
Commit → production
That gives us a consistent view of how efficiently committed code moves through review, merge and deployment.
But a single LTFC number only tells us that something is slow. It does not tell us why. To make the metric useful, we need to break it down into the stages where delay actually accumulates:
Time to review: PR opened → first review
Time to approve: first review → approval
Time to merge: approval → merge/close
Time to deploy: merge → production
This stage-level view makes LTFC operational. It shows whether the issue is reviewer availability, unclear ownership, release batching, CI/CD performance, or manual deployment controls.
Avoid overreacting to snapshots. One slow deployment does not tell us much, but trends do. The useful questions are:
Is lead time improving or worsening over time?
Which teams, repositories or services are consistently slower?
Are certain change types creating most of the delay?
Did a process or tooling change actually reduce waiting time?
Not all changes are comparable. A small UI change, a database migration and a production hotfix should not be treated as the same kind of work. Segmenting by team, repository, work type or risk level helps avoid false conclusions.
Measured well, LTFC becomes a reliable way to understand how efficiently work moves through the delivery system.
How to improve Lead Time for Changes
Improving Lead Time for Changes does not mean asking engineers to code faster. In most teams, the bigger opportunity is reducing the time work spends waiting between stages.
The best place to start is the PR lifecycle.
1. Reduce time to first review
If PRs sit untouched for hours or days, lead time increases before meaningful feedback even begins.
We can reduce this by:
setting clear review ownership
spreading review load across the team
making review work visible in stand-ups or team dashboards
agreeing expected review response times
This is also where key-person dependency often shows up. If the same few engineers review most PRs, the system will slow down whenever they are busy.
2. Make changes smaller
Large PRs are harder to review, harder to test and more likely to create merge conflicts.
Smaller, self-contained changes move through the system faster because they reduce cognitive load at every stage:
reviewers understand the change more quickly
feedback cycles are shorter
testing is simpler
rollback is safer
This is one of the most practical ways to improve LTFC without compromising quality.
3. Standardize review and approval expectations
A slow approval stage often points to unclear standards.
Teams should agree what “good enough to merge” means, including:
when approval is required
who can approve
what checks must pass
when discussion should move out of the PR
Without this, PRs become open-ended debates rather than controlled review points.
4. Remove deployment friction
If work is approved but still waits to reach production, the bottleneck has moved downstream.
Common causes include:
manual deployment gates
fragile CI/CD pipelines
fixed release windows
environment provisioning delays
approval-heavy production controls
Automation helps, but only when it removes waiting time. Automating a slow process without changing the flow rarely fixes the underlying constraint.
5. Balance speed with stability
Improving LTFC should never mean pushing risky changes through the system faster.
LTFC should be viewed alongside:
Change Failure Rate
Mean Time to Recovery
Deployment Frequency
The goal is not speed at any cost. The goal is smaller, safer changes moving through the delivery system with less friction.
When we improve LTFC properly, we improve flow: faster reviews, clearer ownership, fewer queues and a smoother path from commit to production.
Common mistakes with Lead Time for Changes
Even experienced engineering teams misinterpret LTFC. Not because the metric is flawed, but because it’s easy to oversimplify.
Here are the most common traps we see in DevOps environments:
1. Confusing Lead Time, Cycle Time, and Lead Time for Changes
These metrics sound similar but answer very different questions:
Lead Time → idea to delivery
Cycle Time → work started to work completed
Lead Time for Changes → commit to production
When teams blur these, they lose clarity on where delays actually sit. LTFC is specifically a deployment pipeline metric, not a full view of delivery.
2. Optimizing for speed at the expense of quality
Shorter lead times look good – until they don’t.
We’ve seen teams push for faster deployments without balancing:
Change Failure Rate
MTTR
The result? More incidents, more rework, and ironically, longer effective delivery time.
As highlighted in the research behind Accelerate, high-performing teams optimize for speed and stability together, not in isolation. You can explore a summary of the findings here: https://cloud.google.com/devops/state-of-devops
3. Ignoring variability between change types
Not all changes are equal:
A small UI tweak ≠ a database migration
A hotfix ≠ a new feature
Averaging everything into a single LTFC number hides important signals. Strong teams segment by:
change size
risk level
work type
Without that, we risk optimizing the wrong things.
4. Measuring without acting
This is the most common failure mode.
Teams invest in dashboards, track DORA metrics, and… stop there.
But LTFC is a diagnostic metric. Its value comes from:
identifying bottlenecks (e.g. PR reviews, testing queues)
triggering changes in process or ownership
If we’re not using LTFC to drive decisions, we’re just observing delay; not reducing it.
Related DORA metrics
Lead Time for Changes is one of four core DORA metrics. As such, it is often used as part of a ‘balanced scorecard' of agile delivery and DevOps metrics surfaced in real-time.
The other DORA metrics often associated with LTFC are:
How Plandek helps you monitor and reduce Lead Time for Changes
LTFC is one of the clearest indicators of software delivery performance but the number alone rarely tells us where the real constraint sits.
Plandek gives engineering leaders a system-level view of how work actually flows across the SDLC, helping teams understand where committed code is waiting, why bottlenecks are forming, and how those constraints are affecting delivery speed, predictability and quality.
Plandek helps teams move beyond a single aggregate LTFC figure and see where time is being lost across the SDLC, from review delays and queue build-up to handoff bottlenecks and deployment friction.
With Plandek, teams can analyze Lead Time for Changes by:
Author: the individual who created the PR, useful for understanding patterns across engineers and repositories.
Participant: anyone who acted on the PR, helping identify key reviewers and potential dependency risks.
Stage: the specific stage the PR moved through, making it clear where time is being spent.
Repository: useful for comparing lead time across repos and spotting services where changes consistently take longer.
Ticket issue type: based on ticket reference linking, allowing teams to compare lead time for stories, bugs, incidents or other work types.
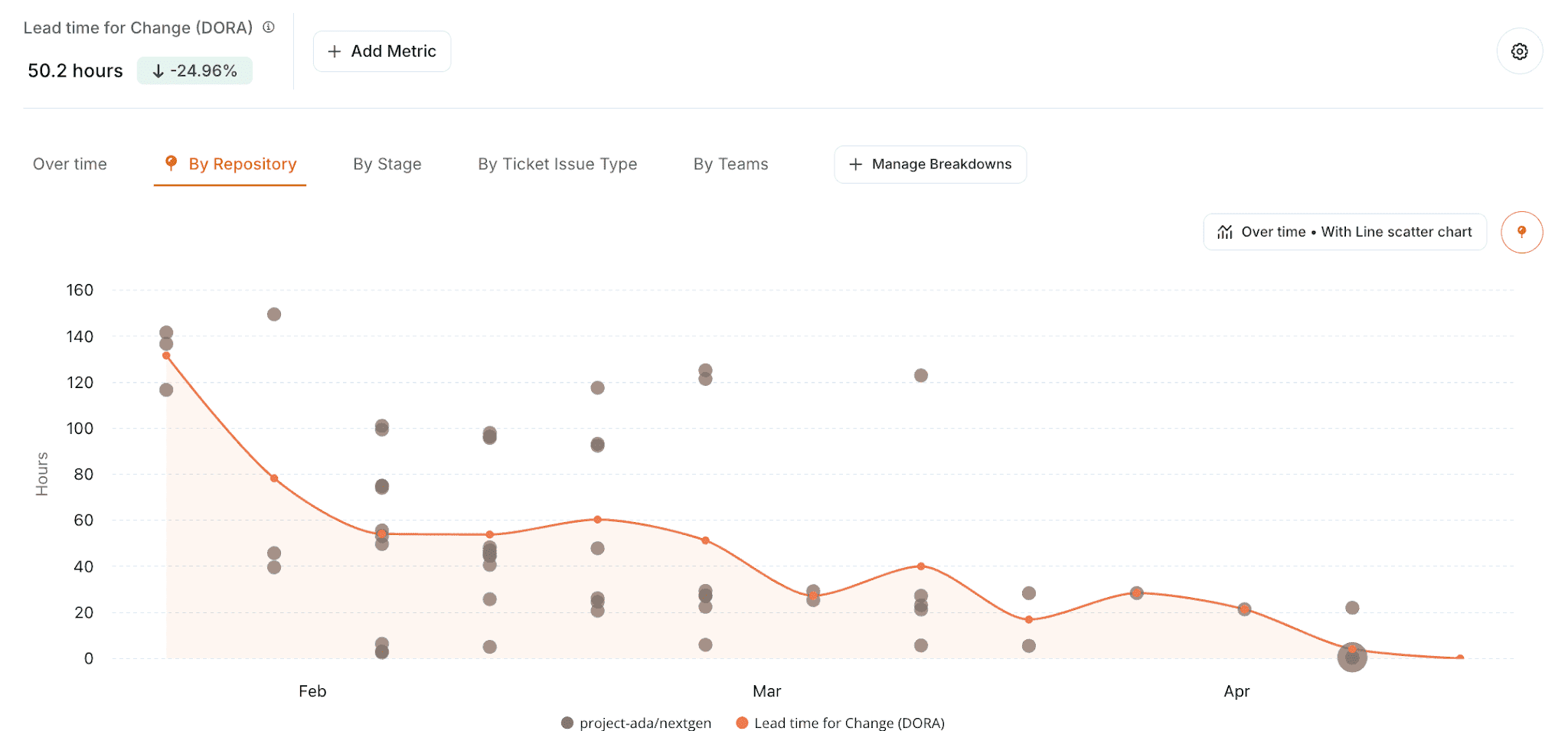
This matters because LTFC problems are rarely obvious from a top-level metric. A high average might be caused by slow review, overloaded approvers, merge delays, release batching, fragile CI/CD pipelines or manual deployment controls.
Instead of looking at LTFC in isolation, Plandek connects delivery data across planning, coding, review, testing and deployment systems to help teams ask better questions:
Where is work waiting?
Who is it waiting on?
Which repos or teams are consistently slower?
Are changes getting stuck before merge or after merge?
Is increased coding throughput improving delivery, or simply creating downstream queues?
Instead of a single aggregate figure, you get a system-level view that shows where work is actually waiting, and why.
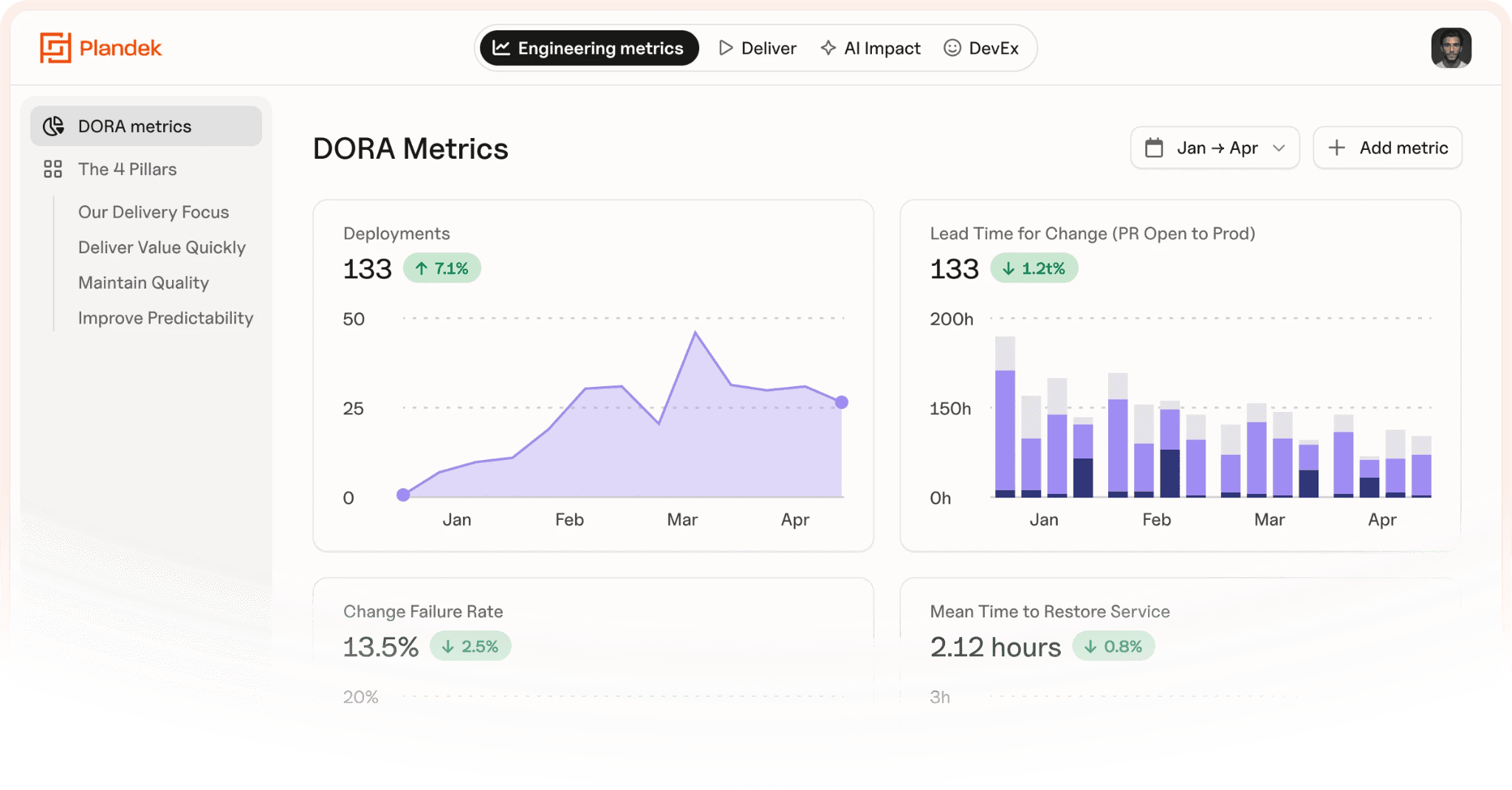
As tools like Copilot, Cursor, Claude and Devin increase coding throughput, bottlenecks often shift downstream into review, testing and release.
Plandek helps you move beyond activity metrics and focus engineering effort on improving flow, reducing blockers and delivering value faster.
👉 See how Plandek helps you monitor DORA metrics and improve productivity across the SDLC
Key takeaways
LTFC measures commit to production, not idea to delivery or work started to completed.
Long lead times usually mean bottlenecks.
Pull requests are a common blocker especially when reviews depend on a few key engineers.
LTFC is a flow metric – it shows where committed code starts to queue.
Improvement starts with stage-level visibility.
Speed must be balanced with stability: LTFC should be read alongside Change Failure Rate, MTTR and Deployment Frequency.
FAQs
How is Lead Time for Changes calculated?
Lead Time for Changes is calculated by measuring the time between a code commit and that change being deployed to production. For better insight, teams should also break it down by review, approval, merge and deployment stages.
How can teams improve Lead Time for Changes?
Teams can improve LTFC by reducing PR wait time, making changes smaller, clarifying review ownership, removing deployment friction and balancing speed with quality.
Is Lead Time for Changes the same as Cycle Time?
No. Cycle Time usually measures work started to work completed, while Lead Time for Changes specifically measures commit to production.
Written by
Charlie Ponsonby
Co-founder & CEO
Charlie Ponsonby is CEO and Co-founder of Plandek, the leading Developer Productivity Insight (DPI) platform that helps software engineering teams drive productivity and transition to AI-led engineering. He writes widely on the opportunities and challenges inherent in the transition to the agentic SDLC. Prior to founding Plandek, Charlie founded Simplydigital, which grew to become the UK's largest broadband and digital services comparison business before being acquired by Europe's largest consumer electronics retailer. He started his career at Accenture and has held senior leadership roles in retail and telco. Charlie holds a degree from the University of Cambridge.



See how your engineering efforts translate into measurable business impact
Measure delivery performance, AI impact, and engineering productivity with hundreds of metrics, OOTB dashboards and custom configurations.









Contact us
UK Office
Unit 313 The Print Rooms, 164-180
Union St, London SE1 0LH
US Office
Floor 4, 1515 Mockingbird Ln,
Charlotte, NC 28209, USA