


Following the high-profile IT failure at British bank TSB – could delivery capability risk management help avoid failed IT launches?
Introduction
The UK bank TSB migrated to a new IT platform in April 2018, following its acquisition by Sabadell in 2015. The new platform was launched in a “big bang” on 20-22 April 2018 when c5m customers were transferred to the new platform. Customers immediately experienced problems accessing their online and mobile banking services, and TSB received 33,000 complaints within ten days, with the platform being described as “unstable and almost unusable” post-launch. The platform was subsequently improved over time, but TSB suffered very significant reputational and commercial damage.
The legal firm Slaughter and May was commissioned to investigate the causes of the failure and published their findings in October 2019. They concluded that:
The new platform was not ready to support TSB’s 5m customers when it launched
SABIS (who built and hosted the platform) was not ready to operate the new platform at launch.
This was despite:
There are seemingly robust programme management disciplines in place and
There is seemingly strong governance and risk management with a “three-line defence” of the Programme team, the Risk Oversight team, and Internal Audit all involved in risk management.
So why did the £325m project fail to deliver immediately post-launch? And could a better understanding of the development capability (and its hidden risk) have helped?
Slaughter and May’s diagnostic – a focus on programme management failure
The Slaughter and May report shows that TSB adopted a fairly traditional “waterfall” software delivery methodology, with the project estimated and planned upfront, with defined milestones building towards a big-bang migration.
The migration date was originally intended for Nov 2017 before being rescheduled to April 2018. However, both times, the planning process was described as “right to left” rather than “left to right” – i.e., TSB started with the desired end date and used this as the key INPUT into the planning process. Whereas a “left to right process” would produce an end date as an OUTPUT of the planning process.
The net effect of this “right to left” approach appears to be that the time planned was inadequate, and the project was rushed (so critical load testing, for example, was rushed). As such, it is characterised as a failure of programme management approach and execution.
Understanding delivery capability risk in complex IT programme management
The overriding theme of Slaughter and May’s diagnostic seems to be that TSB was rushing towards an unachievable go-live date. There was huge stress on the software delivery team, and corners were cut as time ran out – and the net result was a disastrous go-live.
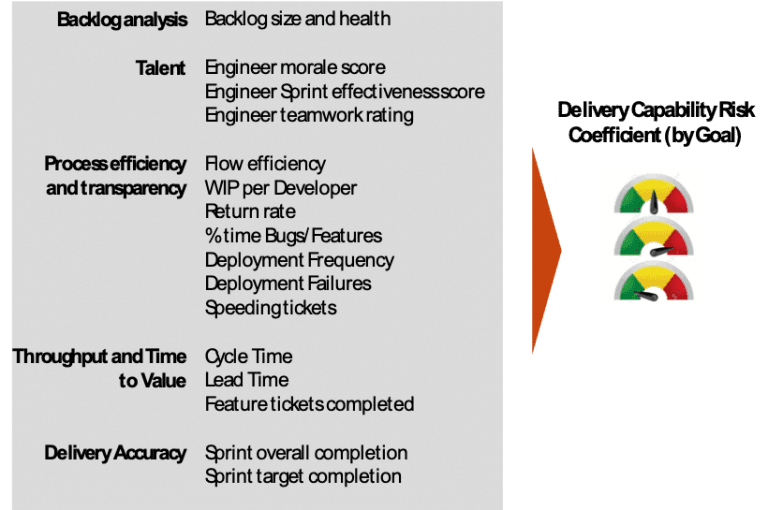
Figure 1. An example of end-to-end software delivery metrics that determine delivery (capability) risk
Understanding delivery capability risk in complex IT programme management. The overriding theme of Slaughter and May’s diagnostic seems to be that TSB was rushing towards an unachievable go-live date. There was a huge stress on the software delivery team, and corners were cut as time ran out – and the net result was a disastrous go-live. So, two critical questions are:
Can you better identify and measure stress and hidden risks within software delivery teams? And related to this question:
Are there warning signals in critical metrics that show that teams are under stress and unlikely to deliver on time?
I believe the answer to both questions is an emphatic “yes” (if you have the tools to collect and analyse the relevant metrics).
Plandek is such a tool. It provides a complete set of end-to-end delivery metrics and analytics to understand and mitigate software delivery capability risk.
It works by mining data from toolsets used by delivery teams (such as Jira, Git, CI/CD tools and Slack) to surface critical metrics to optimise software delivery forecasting, risk management and capability improvement.
As such, it creates a balanced set of metrics that determine delivery capability risk, using both quant data from the underlying tools sets such as Jira, Git, etc – but also from the engineers themselves via constant polling through Slack or other collaboration hubs.
Figure 2. An example of end-to-end software delivery metrics that determine delivery (capability) risk
This balanced scorecard of capability risk metrics adds a new dimension to overall programme risk management.
As Figure 1 shows, these metrics are principally designed for use in an Agile delivery context (with concepts of Cycle Times, Sprint Completion, etc). Still, many can also be applied in a hybrid “Scrumfall” context (often adopted by larger organisations to deliver major projects).
For example:
Metrics relating to backlog health are clearly key in any context (and reveal hidden risks);
real-time understanding of engineer morale and engineer feedback, as regards the delivery process, are also critical leading indicators of (hidden) delivery risk, and so too are;
changes in time spent (and the efficiency of) fixing bugs and technical debt.
These are all “under the bonnet” metrics that, when viewed together, give the experienced Delivery Manager a view on the health of the delivery “engine” – is it firing on all cylinders or running on empty…?
Applying delivery capability risk to overall project risk management frameworks
In the case of TSB, Slaughter and May noted “material limitations in the tracking and monitoring of the programme’s progress”. The project seemed to have relied on quite traditional programme management techniques to map the various workstreams and understand interdependencies and the critical path.
These techniques create well-organised Gantt charts showing the theoretical progress of the project relative to the planned timeframe. However, these techniques cannot effectively track the health of the underlying technology delivery capability.
i.e. the Gantt chart may show that we just hit a key milestone, but understanding the health/stress of the underlying delivery team may paint a very different picture. It may show that this was achieved in an unsustainable way (low morale, declining process efficiency, increasing technical debt, etc) – hence, the team is unlikely to hit the next milestone.
This is why understanding delivery capability risk (i.e., understanding the health of the underlying delivery “engine”) can be a vital extra dimension in complex IT programme management.
Would it save companies such as TSB from such costly mistakes? I think it is unlikely in the case of TSB, as their problems seem to have stemmed from unrealistic “right to left” planning, placing a near-impossible burden on the IT team to deliver.
That said, it may have identified (and clearly quantified) the stress in TSB’s delivery capability, which in turn would have raised warning flags to the Risk Oversight and Internal Audit committees. As such, it may have put more doubt in the minds of those making the key decisions earlier in the process. So perhaps it might just have saved TSB from a costly mistake…
Written by
Charlie Ponsonby
Co-founder & CEO
Charlie started his career as an economist working on trade policy in the developing world, before moving to Accenture in London. He joined the Operating Board of Selfridges, before moving to Open Interactive TV and then Sky where he was Marketing Director until leaving to found Simplifydigital in 2007. Simplifydigital was three times in the Sunday Times Tech Track 100 and grew to become the UK’s largest TV, broadband and home phone comparison service, powering clients including Dixons-Carphone, uSwitch and Comparethemarket. It was acquired by Dixons Carphone plc in April 2016. He co-founded Plandek with Dan Lee in 2018. Charlie was educated at Cambridge University. He lives in London and is married with three children.



See how your engineering efforts translate into measurable business impact
Measure delivery performance, AI impact, and engineering productivity with hundreds of metrics, OOTB dashboards and custom configurations.









Contact us
UK Office
Unit 313 The Print Rooms, 164-180
Union St, London SE1 0LH
US Office
Floor 4, 1515 Mockingbird Ln,
Charlotte, NC 28209, USA